Subdirectory Checkout with git sparse-checkout
It’s very convenient, even necessary, to use a version control system, e.g. CVS or Git. One can go back in history and easily trace the changes (especially) when something goes wrong. Git, being a distributed system, can be used to develop locally and once your work is ready, you can push it upstream to your repository, where it is available to the others to see or to pull. Next, you’d probably want to apply the patches to the production server, where the software is actually deployed. Most often, this is done uploading the files via FTP.
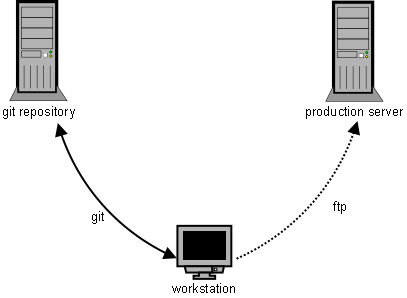
This approach is common and usually serves well. Over the years, however, I have found that there is space for “human error”. It happened a few times that I forgot to upload a file that was part of the patch and had to deal with the consequent problems later. Then it occurred to me that I could make use of the version control features for deployment as well. You need shell access, of course, but where possible, this approach can be very convenient and it can eliminate the human factor.
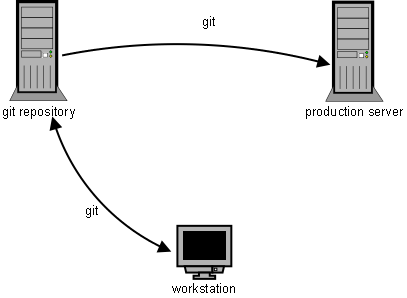
Now, it can be useful sometimes not to checkout all the contents of the repository on the production server. Let’s say you have this directory structure:
| |__Documentation |__SQL_structure_files |__public_html
where only the public_html directory needs to be deployed. To be able to check out only some part of the repository you can use git sparse-checkout in the directory on the production server where you want to put the files:
git init git remote add origin git@repo.example.com:/git/repo_name git config core.sparsecheckout true echo public_html >> .git/info/sparse-checkout git pull origin master
On the first line, you initialize a new repository. Then you add your remote repository to the list of remotes. On the third line, you enable the sparsecheckout feature that allows you to check out partial content only. On the fourth line, you define what directories you want to check out, it’s only public_html in this case. Once you’re done, you can get the repository contents and checkout the allowed contents, i.e. to pull.